
O Spring Batch é o 'canivete suíço' da JVM para lidar com grandes volumes de dados. Neste artigo, aprenda a configurar essa ferramenta robusta para resolver um desafio real: consolidar relatórios de vendas de diversas concessionárias em uma única solução eficiente.
Contexto
O ecossistema do Spring surpreende por ser um canivete suíço, e não seria diferente no mundo batch, onde lidamos com grandes volumes de dados para executar as mais diversas rotinas em ambientes corporativos.
Seja no fechamento de folha de pagamento, no envio de campanhas via push notification ou em migrações/convivência entre sistemas, o Spring Batch brilha como uma alternativa robusta rodando dentro da JVM.
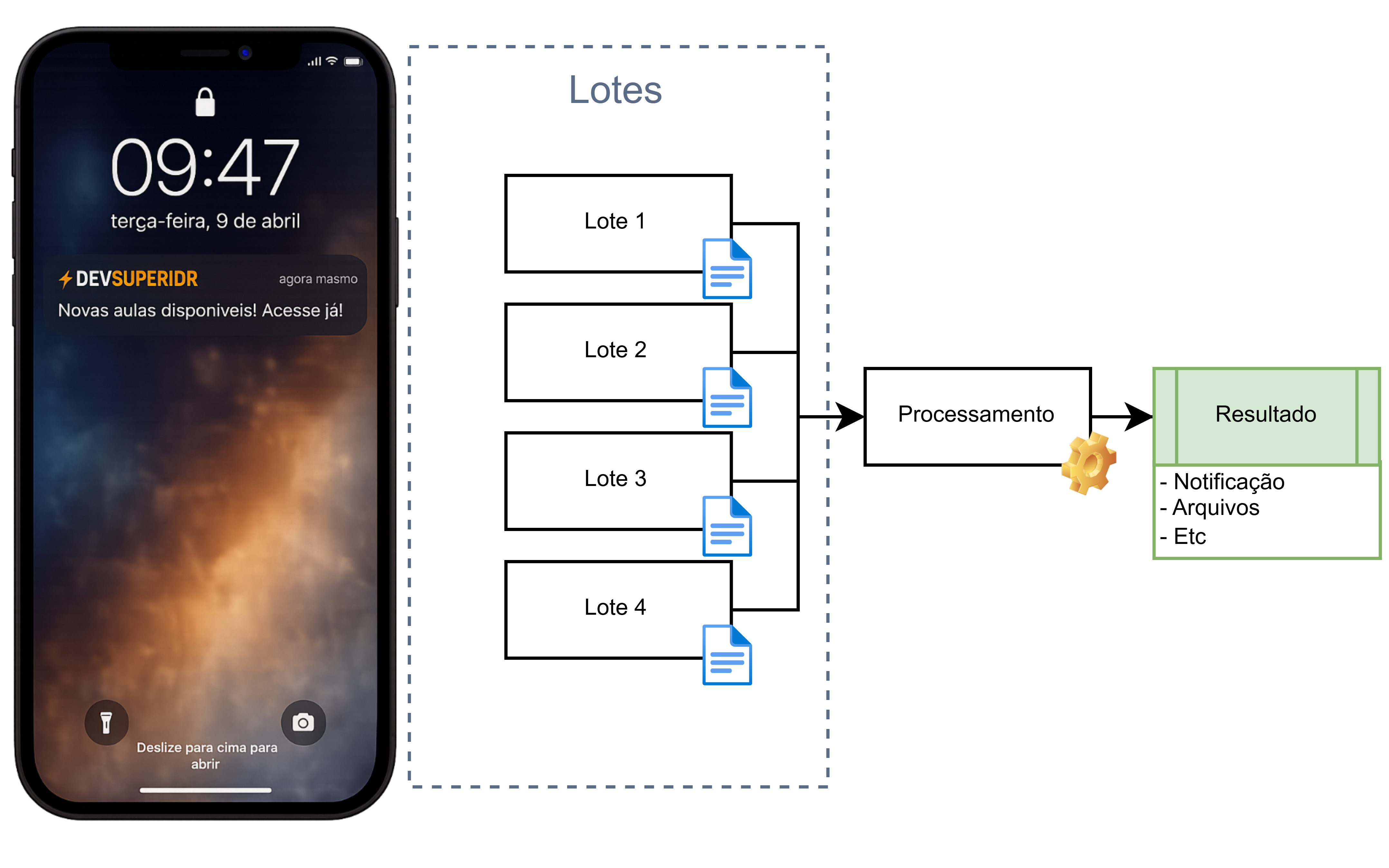
Neste artigo, você vai aprender a usar o Spring Batch para gerar um relatório (report) de vendas consolidado a partir dos relatórios individuais de várias concessionárias filiais espalhadas pelo país. Vem comigo!
O que são sistemas batch?
O termo batch pode parecer estranho quando você escuta pela primeira vez, mas dá para traduzi-lo como “lote” (e isso ajuda bastante).
Um sistema batch executa o processamento de uma quantidade finita de dados, normalmente sem interação humana durante a execução, por meio de:
- execuções agendadas (data/hora);
- gatilhos/estímulos externos (ex.: liberação de uma turma/aula, solicitação de geração de relatório, fechamento de ciclo etc.).
Batch vs. API REST / Microserviços
É importante notar a diferença entre API REST/microserviços e sistemas batch.
Pense assim: uma API REST/Microserviços é como um Uber (você chama agora e é atendido na hora), enquanto um Sistema Batch é como um ônibus (tem horário para passar e leva “todo mundo” de uma vez). Ambos têm propósitos distintos e são aplicáveis a cenários diferentes dentro de um negócio.
- On-demand vs. Agendado: o Uber reage ao seu clique; o ônibus segue um cronograma.
- Individual vs. Coletivo: a API trata o seu pedido; o batch trata o volume acumulado.
Demanda de mercado
Você já ouviu falar de COBOL? Essa linguagem foi uma das precursoras no ambiente batch e ainda é muito utilizada no sistema financeiro mundial. Segundo a IBM (responsável pelo COBOL), são cerca de 3 trilhões de dólares sendo processados diariamente por código COBOL.
O COBOL, felizmente, vem sendo descontinuado na maior parte das empresas. A migração acelerada para nuvem pública (AWS, Azure, GCP etc.), somada à escassez de profissionais no mercado e ao suporte exclusivo da IBM, são forças motrizes desse ciclo. O Itaú anunciou recentemente a intenção de modernizar 100% do banco em nuvem pública até 2028.
No mundo Java, usamos o Spring Batch como framework para dar a robustez necessária aos processamentos em lote. Ele é projetado para lidar com cenários em que “falhar não é uma opção”, mas se falhar, informar com precisão onde parou para permitir retomada.
Além disso, o Spring Batch se encaixa bem em arquiteturas modernas: ele pode executar de forma cloud native, com integração com orquestradores de containers e sendo agnóstico de fornecedor (executável em diferentes ambientes/clouds).
O Bradesco, um dos maiores bancos da América Latina, utiliza o Spring Batch em operações batch diariamente como alternativa moderna ao COBOL.
Conhecer como processos batch funcionam no Spring Batch me parece uma boa ideia, hein? 😉
Nosso caso de uso
Vamos transformar um problema real em solução usando o Spring Batch para resolver um problema do negócio do nosso cliente.
O nosso cliente é a maior rede de concessionárias de carros do Brasil chamada Aurora Car Dealer, uma grande rede (fictícia) que possui lojas em 11 estados do país.
O problema
A Aurora Car Dealer precisa automatizar a geração do seu principal relatório de vendas, que hoje é feito manualmente no Excel.
Semanalmente as filiais da Aurora (Aurora Rio, Aurora SP, etc.) enviam seus relatórios individuais de vendas para a matriz da Aurora Car Dealer consolidar a informação e criar seu relatório de performance de vendas único, de todo Brasil.
Como o processo hoje é manual, os acionistas da Aurora têm reclamado dos constantes atrasos na disponibilização da informação, dificultando o acompanhamento e a tomada de decisão.
Dado esse problema, o cliente deseja modernizar esse processo e possui alguns requisitos:
- Automação da execução
- Seja possível monitorar
- Possua histórico de execução
- Leitura automatizada de múltiplos arquivos
- Escalabilidade automática caso surjam novas filiais
Por que o Spring Batch é necessário aqui?
Esse é um cenário clássico de processamento em lote (batch): toda semana precisamos ler muitos arquivos, padronizar/validar os dados, consolidar e gerar um único relatório para a matriz. Com confiabilidade e rastreabilidade.
O Spring Batch se encaixa muito bem porque ele entrega, de forma “pronta”:
- Orquestração de um Job (pipeline) com etapas bem definidas: leitura → processamento → gravação.
- Leitura de múltiplos arquivos (por filial) de forma padronizada e automatizada, sem depender de Excel manual.
- Validação, tratamento de erros e tolerância a falhas (skip/retry), evitando que um arquivo ruim derrube todo o processo.
- Reprocessamento seguro e retomada (restartability): se falhar no meio, conseguimos continuar de onde parou sem refazer tudo.
- Histórico e auditoria via JobRepository: quem executou, quando, quanto processou, o que falhou e por quê.
- Monitoramento e visibilidade operacional (status do job, métricas, logs), facilitando a vida de quem opera.
- Escalabilidade quando o volume crescer: dá para paralelizar por filial/arquivo (partitioning/multi-thread) e suportar novas lojas sem redesenhar o fluxo.
Em resumo: o Spring Batch transforma esse processo manual e frágil em um processo repetível, observável e escalável, alinhado aos requisitos do negócio.
Spring Batch em ação
Vamos entender como aplicar o Spring Batch na resolução desse problema.
Esse é o diagrama em alto nível da solução:
As filiais exportam arquivos .csv no seguinte formato:
dealer_id,sale_date,model,payment_type,sale_price_brl
D001,2026-02-07,Serra,Financiamento,149309.28
D001,2026-02-02,Lume,TED,96188.77
D002,2026-02-04,Lume,Consórcio,99056.68
...
D005,2026-02-03,Touro,PIX,229200.22Você encontra os arquivos de exemplo na pasta
src/main/resources/filial-reportdo projeto.
E a matriz gostaria de um relatório de vendas único, informando quantos modelos de cada carro foram vendidos e qual o valor total dessas vendas, seguindo o formato:
dealer_name,model,units_sold,revenue_brl
Aurora Prime Paulista,Serra,1,149309.28
Aurora Prime Paulista,Lume,1,96188.77
Aurora Rio Mar,Lume,1,99056.68
Aurora Curitiba Norte,Touro,1,229200.22Vamos exportar o report final para a pasta
src/main/resources/matriz-reportdo projeto.
- application.properties: conexão com H2, caminhos de entrada e saída, e inicialização do banco.
Mão na massa
O nosso projeto está disponível no GitHub do Blog, acesse aqui. Nesta seção vamos explorar o projeto que já criamos para entender o funcionamento do Spring Batch.
Esse projeto utiliza:
- Java 25
- Maven
- Spring Boot 4.0.2
- Spring Batch
- Spring JDBC
- H2 Database
Importe seu projeto na IDE de sua preferência (Spring Tools, IntelliJ) e vamos começar.
Subindo os dados do negócio
Para nosso exemplo, toda informação está disponível no diretório src/main/resources.
- schema-all.sql: estrutura da tabela
dealers, onde existe "de-para" do ID para nome da concessionária. - data.sql: dados do ID vs Nome das filiais.
Conteúdo principal do application.properties:
spring.application.name=car-dealer
spring.datasource.url=jdbc:h2:mem:cardealer
spring.datasource.username=sa
spring.datasource.password=
spring.sql.init.mode=always
spring.sql.init.schema-locations=classpath:schema-all.sql
spring.sql.init.data-locations=classpath:data.sql
app.filial-report-pattern=file:src/main/resources/filial-report/*.csv
app.matriz-report-file=src/main/resources/matriz-report/sales-report.csvNessa configuração, inicializamos o banco de dados em memória e setamos o caminho dos dados (filial e matriz).
Conteúdo do schema-all.sql:
DROP TABLE IF EXISTS dealers;
CREATE TABLE dealers (
dealer_id VARCHAR(10) NOT NULL PRIMARY KEY,
dealer_name VARCHAR(120) NOT NULL
);Estamos apontando esse arquivo em
spring.sql.init.schema-locationsdoapplication.properties.
Conteúdo do data.sql:
INSERT INTO dealers (dealer_id, dealer_name) VALUES
('D001', 'Aurora Prime Paulista'),
('D002', 'Aurora Rio Mar'),
('D003', 'Aurora Minas Centro'),
('D004', 'Aurora Sul Cristal'),
('D005', 'Aurora Curitiba Norte'),
('D006', 'Aurora Salvador Atlântico'),
('D007', 'Aurora Recife Boa Viagem'),
('D008', 'Aurora Fortaleza Dunas'),
('D009', 'Aurora Brasília Eixo'),
('D010', 'Aurora Goiânia Anhanguera'),
('D011', 'Aurora Manaus Rio Negro'),
('D012', 'Aurora Belém Guajará');Estamos apontando esse arquivo em
spring.sql.init.data-locationsdoapplication.properties.
Essa é nossa configuração mínima.
Camadas básicas do Spring Batch
Para se orientar, pense no batch como um pipeline que sai de um Job, passa por um Step e percorre as camadas de leitura, processamento e escrita.
- JobRepository (infraestrutura): persiste metadados de execução (tabelas
BATCH_*, parâmetros, status, timestamps) e dá suporte a restart. Um repository atende N jobs e N steps. - Job Launcher (execução): dispara o job e registra a execução no
JobRepository. - Job: representa o processo completo. Um launcher pode disparar N jobs; um job pode ser executado N vezes.
- Step: uma etapa dentro do job. Um job tem 1..N steps.
- ItemReader: lê os dados de entrada. Um step usa um reader.
- ItemProcessor: transforma os dados (opcional). Um step pode ter 0..1 processor.
- ItemWriter: grava o resultado. Um step usa um writer.
O JobLauncher cria a JobExecution e chama o Job. No Spring Boot, o JobLauncherApplicationRunner dispara automaticamente quando a aplicação sobe.
O JobRepository é o registro oficial do batch: ele guarda o histórico de execuções, parâmetros usados e status final, e é isso que permite retomar jobs com segurança.
Classes do projeto e o que cada método faz
Abaixo vamos aprofundar nos conceitos de cada classe do nosso projeto, e é importante que você já tenha feito o clone do projeto no seu ambiente local, repare em que pacote estamos criando cada classe, esses pacotes refletem as camadas do Spring Batch para facilitar o entendimento.
CarDealerApplication Classe principal do Spring Boot que inicia a aplicação e dispara o job.
package br.com.devsuperior.car_dealer;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class CarDealerApplication {
// Inicializa o Spring Boot e dispara o job configurado.
public static void main(String[] args) {
SpringApplication.run(CarDealerApplication.class, args);
}
}O @SpringBootApplication liga o auto-config e sobe o contexto. Ao subir, o JobLauncherApplicationRunner identifica o job configurado e executa.
config.SalesReportJobConfig Configuração do Job e do Step principal.
package br.com.devsuperior.car_dealer.config;
import br.com.devsuperior.car_dealer.domain.SaleRecord;
import br.com.devsuperior.car_dealer.writer.SalesReportWriter;
import org.springframework.batch.core.job.Job;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.Step;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.infrastructure.item.ItemProcessor;
import org.springframework.batch.infrastructure.item.file.MultiResourceItemReader;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
public class SalesReportJobConfig {
// Define o job principal do batch.
@Bean
public Job salesReportJob(JobRepository jobRepository, Step salesReportStep) {
return new JobBuilder("salesReportJob", jobRepository)
.start(salesReportStep)
.build();
}
// Monta o step com reader, processor, writer e transacao.
@Bean
public Step salesReportStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager,
MultiResourceItemReader<SaleRecord> saleReader,
ItemProcessor<SaleRecord, SaleRecord> saleProcessor,
SalesReportWriter writer) {
return new StepBuilder("salesReportStep", jobRepository)
.<SaleRecord, SaleRecord>chunk(100)
.reader(saleReader)
.processor(saleProcessor)
.writer(writer)
.transactionManager(transactionManager)
.build();
}
}A anotação @Configuration indica classe de configuração, base para declarar o nosso processo batch.
Já @Bean registra o Step no contexto do Spring. O Step faz referência para as classes de reader, processor e writer.
O chunk(100) define o tamanho de transação: o Spring lê, processa e grava 100 itens por commit.
reader.SaleReaderConfig Configuração dos readers usados para varrer e mapear os CSVs.
package br.com.devsuperior.car_dealer.reader;
import br.com.devsuperior.car_dealer.domain.SaleRecord;
import java.io.IOException;
import java.util.Arrays;
import java.util.Comparator;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.infrastructure.item.file.FlatFileItemReader;
import org.springframework.batch.infrastructure.item.file.MultiResourceItemReader;
import org.springframework.batch.infrastructure.item.file.builder.FlatFileItemReaderBuilder;
import org.springframework.batch.infrastructure.item.file.mapping.RecordFieldSetMapper;
import org.springframework.batch.infrastructure.item.file.transform.DelimitedLineTokenizer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import org.springframework.core.io.support.ResourcePatternResolver;
@Configuration
public class SaleReaderConfig {
// Agrega multiplos arquivos CSV em um unico reader.
@Bean
@StepScope
public MultiResourceItemReader<SaleRecord> saleReader(ResourcePatternResolver resolver,
FlatFileItemReader<SaleRecord> saleFileReader,
@Value("${app.filial-report-pattern}") String pattern)
throws IOException {
Resource[] resources = resolver.getResources(pattern);
Arrays.sort(resources, Comparator.comparing(Resource::getFilename));
MultiResourceItemReader<SaleRecord> reader = new MultiResourceItemReader<>(saleFileReader);
reader.setResources(resources);
return reader;
}
// Le e mapeia cada linha do CSV para SaleRecord.
@Bean
@StepScope
public FlatFileItemReader<SaleRecord> saleFileReader() {
RecordFieldSetMapper<SaleRecord> mapper = new RecordFieldSetMapper<>(SaleRecord.class);
return new FlatFileItemReaderBuilder<SaleRecord>()
.name("saleFileReader")
.encoding("UTF-8")
.linesToSkip(1)
.delimited()
.delimiter(DelimitedLineTokenizer.DELIMITER_COMMA)
.names("dealerId", "saleDate", "model", "paymentType", "salePriceBrl")
.fieldSetMapper(mapper)
.build();
}
}@StepScope cria o bean no momento em que o step roda, permitindo usar parâmetros do job e garantindo que o reader/processor/writer não compartilhe estado entre execuções.
O MultiResourceItemReader busca vários arquivos usando o pattern do application.properties. O FlatFileItemReader mapeia cada linha do CSV para a classe modelo SaleRecord.
processor.SaleRecordProcessor Processor simples que normaliza campos antes da agregação.
package br.com.devsuperior.car_dealer.processor;
import br.com.devsuperior.car_dealer.domain.SaleRecord;
import org.springframework.batch.infrastructure.item.ItemProcessor;
import org.springframework.stereotype.Component;
@Component
public class SaleRecordProcessor implements ItemProcessor<SaleRecord, SaleRecord> {
// Normaliza dados do CSV antes da escrita.
@Override
public SaleRecord process(SaleRecord item) {
String model = item.model() == null ? null : item.model().trim();
String paymentType = item.paymentType() == null ? null : item.paymentType().trim();
return new SaleRecord(
item.dealerId(),
item.saleDate(),
model,
paymentType,
item.salePriceBrl()
);
}
}Ao implements ItemProcessor<I,O>, o Spring chama o process para cada item. Como SaleRecord é imutável, retornamos uma nova instância com os campos normalizados.
domain.SaleRecord Record imutável que representa uma venda lida do CSV.
package br.com.devsuperior.car_dealer.domain;
import java.math.BigDecimal;
// Representa uma venda lida do CSV.
public record SaleRecord(
String dealerId,
String saleDate,
String model,
String paymentType,
BigDecimal salePriceBrl
) {
}Por ser record, o Java gera acessores (dealerId(), saleDate() etc.) automaticamente.
domain.ReportLine Record que agrega vendas por filial e modelo.
package br.com.devsuperior.car_dealer.domain;
import java.math.BigDecimal;
import java.math.RoundingMode;
public record ReportLine(
String dealerName,
String model,
int unitsSold,
BigDecimal revenueBrl
) {
// Cria uma linha agregada com valores iniciais zerados.
public ReportLine(String dealerName, String model) {
this(dealerName, model, 0, BigDecimal.ZERO);
}
// Soma uma venda e retorna um novo agregado.
public ReportLine addSale(BigDecimal salePrice) {
return new ReportLine(dealerName, model, unitsSold + 1, revenueBrl.add(salePrice));
}
// Converte o agregado para uma linha CSV.
public String toCsv() {
BigDecimal rounded = revenueBrl.setScale(2, RoundingMode.HALF_UP);
return dealerName + "," + model + "," + unitsSold + "," + rounded.toPlainString();
}
}O record garante imutabilidade. A cada venda, criamos um novo agregado com addSale.
writer.SalesReportWriter Writer que consolida as vendas e grava o CSV final da matriz.
package br.com.devsuperior.car_dealer.writer;
import br.com.devsuperior.car_dealer.domain.ReportLine;
import br.com.devsuperior.car_dealer.domain.SaleRecord;
import java.io.BufferedWriter;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import org.springframework.batch.core.ExitStatus;
import org.springframework.batch.core.listener.StepExecutionListener;
import org.springframework.batch.core.step.StepExecution;
import org.springframework.batch.infrastructure.item.Chunk;
import org.springframework.batch.infrastructure.item.ItemWriter;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Component;
@Component
public class SalesReportWriter implements ItemWriter<SaleRecord>, StepExecutionListener {
private final JdbcTemplate jdbcTemplate;
private final String outputFile;
private Map<String, String> dealerNames = new HashMap<>();
private final Map<String, ReportLine> report = new LinkedHashMap<>();
// Injecao de dependencias e caminho do arquivo de saida.
public SalesReportWriter(JdbcTemplate jdbcTemplate,
@Value("${app.matriz-report-file}") String outputFile) {
this.jdbcTemplate = jdbcTemplate;
this.outputFile = outputFile;
}
// Carrega o mapa de filiais antes do step iniciar.
@Override
public void beforeStep(StepExecution stepExecution) {
dealerNames = jdbcTemplate.query("SELECT dealer_id, dealer_name FROM dealers", rs -> {
Map<String, String> map = new HashMap<>();
while (rs.next()) {
map.put(rs.getString("dealer_id"), rs.getString("dealer_name"));
}
return map;
});
}
// Agrega vendas por filial e modelo durante o processamento.
@Override
public void write(Chunk<? extends SaleRecord> items) {
for (SaleRecord item : items) {
String dealerName = dealerNames.getOrDefault(item.dealerId(), item.dealerId());
String key = dealerName + "|" + item.model();
report.compute(key, (k, existing) -> {
ReportLine base = existing == null ? new ReportLine(dealerName, item.model()) : existing;
return base.addSale(item.salePriceBrl());
});
}
}
// Grava o relatorio final ao termino do step.
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
writeReport();
return ExitStatus.COMPLETED;
}
// Escreve o CSV consolidado no destino.
private void writeReport() {
Path path = Path.of(outputFile);
try {
Path parent = path.getParent();
if (parent != null) {
Files.createDirectories(parent);
}
List<ReportLine> lines = new ArrayList<>(report.values());
lines.sort(Comparator.comparing(ReportLine::dealerName)
.thenComparing(ReportLine::model));
try (BufferedWriter writer = Files.newBufferedWriter(path, StandardCharsets.UTF_8)) {
writer.write("dealer_name,model,units_sold,revenue_brl");
writer.newLine();
for (ReportLine line : lines) {
writer.write(line.toCsv());
writer.newLine();
}
}
} catch (IOException e) {
throw new IllegalStateException("Failed to write report to " + outputFile, e);
}
}
}Ao realizar o implements ItemWriter o Spring chama write a cada chunk. Já a interface StepExecutionListener permite executar código antes e depois do step (beforeStep e afterStep). O writer busca os nomes das filiais no H2 via JdbcTemplate, agrega em memória e grava o CSV final no caminho configurado.
Executando o job
Você pode executar o código usando a invocação do plugin do spring-boot via Maven:
./mvnw spring-boot:runOu simplesmente executar a classe principal no método main na sua IDE:
CarDealerApplication.main(...)A aplicação sobe, o job é executado e o processo finaliza após concluir o step. Em produção, normalmente um agendador dispara a aplicação no horário combinado (cron, Kubernetes CronJob, Airflow, Control-M, Cloud Scheduler etc.).
E confira o arquivo gerado em src/main/resources/matriz-report/sales-report.csv. O arquivo bate com a especificação do nosso projeto.
dealer_name,model,units_sold,revenue_brl
Aurora Prime Paulista,Serra,1,149309.28
Aurora Prime Paulista,Lume,1,96188.77
Aurora Rio Mar,Lume,1,99056.68
Aurora Curitiba Norte,Touro,1,229200.22Conclusão
Soluções Batch são requisitos da maior parte dos negócios de grande e médio porte, saber se posicionar no tema é fundamental para todo desenvolvedor. Mesmo em empresas que não usam Spring Batch como solução, os conceitos aprendidos no estudo do framework são aplicáveis a todas as ferramentas de mercado.
E aí, curtiu? Esse é um exemplo enxuto, mas já mostra o poder do Spring Batch no dia a dia.
O código completo está no repositório do blog.