
Chegou task nova: criar uma funcionalidade de IA. A boa notícia? você não precisa aprender Python ou virar cientista de dados e nem chamar a API da Anthropic na unha. O Spring AI traz a IA generativa para dentro do mundo Spring com as mesmas ferramentas que você já usa todo dia, injeção de dependência, beans e auto configuração. Neste artigo a gente constrói, do zero, um assistente de RH que responde às perguntas dos colaboradores lendo as políticas reais da empresa, sem inventar nada, usando Claude, RAG e PostgreSQL.
Imagine a rotina do RH de uma empresa com centenas de colaboradores. Todo dia chegam as mesmas perguntas, do tipo "quantos dias de licença-paternidade eu tenho?", "qual o valor do vale-refeição?", "como funciona o banco de horas?". A resposta está sempre no mesmo lugar, nas políticas internas, mas alguém precisa parar o que está fazendo e responder de novo. E de novo. O time vira um call center de FAQ.
E se existisse uma IA que respondesse essas perguntas pelo documento oficial, 24 horas por dia, sem inventar nada? Não um chatbot genérico que chuta respostas, mas um assistente que lê as políticas reais da empresa e só fala o que está escrito lá. Quando não souber, ele admite e encaminha para um humano. É exatamente isso que vamos construir.
Conceito: Spring AI e RAG
Modelos de linguagem como o Claude são impressionantes, mas têm um limite conhecido, eles não conhecem os documentos internos da sua empresa. Se você perguntar a um LLM cru "qual o vale-refeição da Aurora Car Dealer?", ele não tem como saber, essa informação nunca esteve na base de treino dele. Na melhor das hipóteses ele admite que não sabe, na pior, ele alucina um valor plausível e errado.
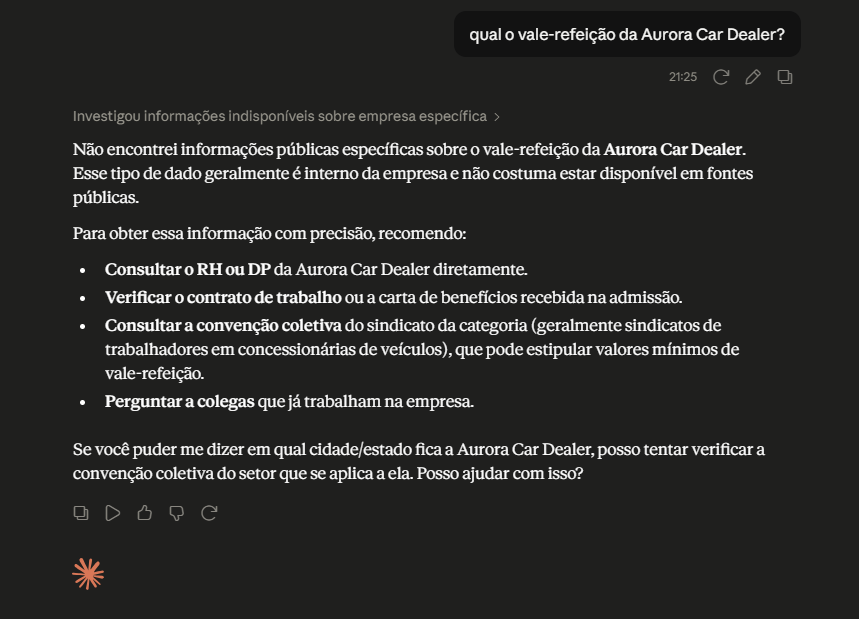 um LLM puro não conhece os dados internos da sua empresa e, no melhor caso, admite que não sabe
um LLM puro não conhece os dados internos da sua empresa e, no melhor caso, admite que não sabe
A solução chama-se RAG (Retrieval Augmented Generation). A ideia é simples e poderosa. Antes de o modelo responder, você busca os trechos relevantes dos seus documentos e injeta esse contexto junto da pergunta. O LLM passa a responder ancorado nos fatos da empresa, e não na imaginação dele.
Para isso funcionar, precisamos de três peças:
- Embeddings, que transformam texto em vetores numéricos. Frases com significado parecido ficam próximas no espaço vetorial, e é assim que a máquina mede "similaridade de sentido".
- Vector Store, o banco que armazena esses vetores e faz busca por proximidade. Usaremos PostgreSQL com a extensão PgVector.
- Retrieval, o passo em que o sistema gera o embedding da pergunta, busca os trechos mais próximos no vector store e entrega tudo ao modelo.
O Spring AI é a camada que cola essas peças de forma idiomática para quem já vive no ecossistema Spring. Em vez de montar requisições HTTP na mão, você programa contra abstrações de alto nível.
ℹ️ Glossário rápido
ChatClient, a porta de entrada para conversar com o modelo, no estilo fluente doWebClient/RestClient.EmbeddingModel, o componente que vetoriza texto.VectorStore, a abstração de banco vetorial (no nosso caso, PgVector).- Advisor, um interceptador na pipeline do
ChatClient, a mesma ideia dosFiltereHandlerInterceptordo MVC.- Grounding, "ancorar" a resposta nos trechos recuperados, para o modelo falar só o que está no documento.
Veja o fluxo completo do conceito, da ingestão do documento até a resposta ancorada.
No fim do fluxo está a resposta ancorada. Ancorada quer dizer presa aos fatos. O modelo responde a partir dos trechos recuperados do seu documento, e não da memória de treino dele. Se um trecho não veio do PgVector, ele não entra na resposta. É isso que evita o assistente devolver um valor de vale-refeição plausível, porém errado.
Mercado e Empregabilidade
Isso não é exercício de laboratório, é o que as empresas brasileiras já colocam em produção. O Grupo Boticário construiu uma assistente de vendas com a mesma receita deste artigo, o modelo Anthropic Claude para conversar e embeddings vetoriais para busca semântica no catálogo. O resultado, segundo a própria AWS, foi um aumento de 46% na conversão de vendas logo no primeiro mês, com ticket médio 7,4% maior entre quem usou a assistente.
Repare na arquitetura, Claude mais embeddings mais recuperação por similaridade. Troque "catálogo de produtos" por "manual de RH" e você tem exatamente o que vamos montar aqui. Quem aprende RAG com Spring AI agora não está estudando uma tecnologia de nicho, está se posicionando onde grandes players brasileiros já estão investindo e contratando.
Caso de Uso: Aurora Car Dealer
Nosso laboratório é a Aurora Car Dealer (fictícia), uma rede de concessionárias com mais de 280 colaboradores em quatro unidades de Minas Gerais e sede em Belo Horizonte. Como toda empresa desse porte, ela tem um Manual de Políticas de RH (versão 4.2, de janeiro de 2025) que ninguém lê inteiro, mas todo mundo precisa consultar.
A proposta é um assistente de autoatendimento que responde dúvidas dos colaboradores ancorado somente nas políticas oficiais. Se a pergunta é sobre férias, ele cita o que o manual diz sobre férias. Se a pergunta for "qual a senha do Wi-Fi de visitantes?", algo que não está no documento, ele não chuta. Quando a resposta não está nas políticas, o assistente reconhece o limite e direciona para o canal certo, com e-mail e telefone do RH.
Projeto Hands-on
Requisitos
Requisitos funcionais:
- Ingerir o PDF de políticas e indexá-lo no vector store.
- Responder perguntas via chat, ancorado nos trechos recuperados.
- Manter histórico de conversa por sessão.
- Entregar a resposta em streaming (token a token).
- Reconhecer quando a informação não está no documento e direcionar a um humano.
Requisitos não funcionais:
- Provedor de chat trocável por configuração, sem mexer no código.
- Respostas quase determinísticas, com temperatura baixa, afinal é RH.
ℹ️ Temperatura é o parâmetro que controla o quanto o modelo "arrisca" ao escolher as próximas palavras.
- Temperatura alta (
0.8a1.0), mais criatividade e variação, ótima para brainstorm e escrita criativa.- Temperatura baixa (
0.0a0.2), mais foco e previsibilidade, a mesma pergunta tende a gerar a mesma resposta. É o que queremos aqui.
Stack do projeto:
- Java 25, Maven e Spring Boot 4.1.0.
- Spring MVC (Tomcat), via
spring-boot-starter-webmvc. - Spring AI 2.0.0 (chat, embeddings, vector store e memória).
- PgVector (PostgreSQL) como vector store.
- Redis Stack para memória de conversa.
- Ollama com
bge-m3para gerar os embeddings. - Docker e docker-compose para a infraestrutura.
Antes de rodar, você precisa de três coisas:
- JDK 25 instalado e no PATH. O
mvnwbaixa o Maven, mas não o Java, e o Ollama roda em container, então não precisa instalar nada nativo além do JDK. - Docker e Docker Compose, que sobem o Postgres, o Redis e o Ollama. No Windows, o Docker Desktop precisa estar aberto.
- Uma chave da API da Anthropic. Crie uma conta em console.anthropic.com, gere uma API key, adicione créditos e guarde o valor na variável de ambiente
ANTHROPIC_API_KEY.
O modelo que usaremos é o claude-haiku-4-5, que custa cerca de US$ 1,00 por milhão de tokens de entrada e US$ 5,00 por milhão de saída, barato e ideal para perguntas e respostas. O embedding roda localmente no Ollama, então não há custo de API para vetorizar texto.
Dois caminhos: clonar ou construir do zero
Você pode seguir o artigo de dois jeitos. O caminho rápido é clonar o repositório e rodar.
git clone https://github.com/devsuperior/blog.git
cd blog/articles/spring-ai-em-acao-assistente-de-rh-com-rag-e-claude/projects/hr-assistantEsse é o esqueleto do projeto no Spring Initializr. Preencha os campos exatamente como na imagem, Maven, Java 25, Spring Boot 4.1.0, packaging Jar e configuração YAML, com Group igual a br.com.devsuperior e Artifact igual a hr_assistant.
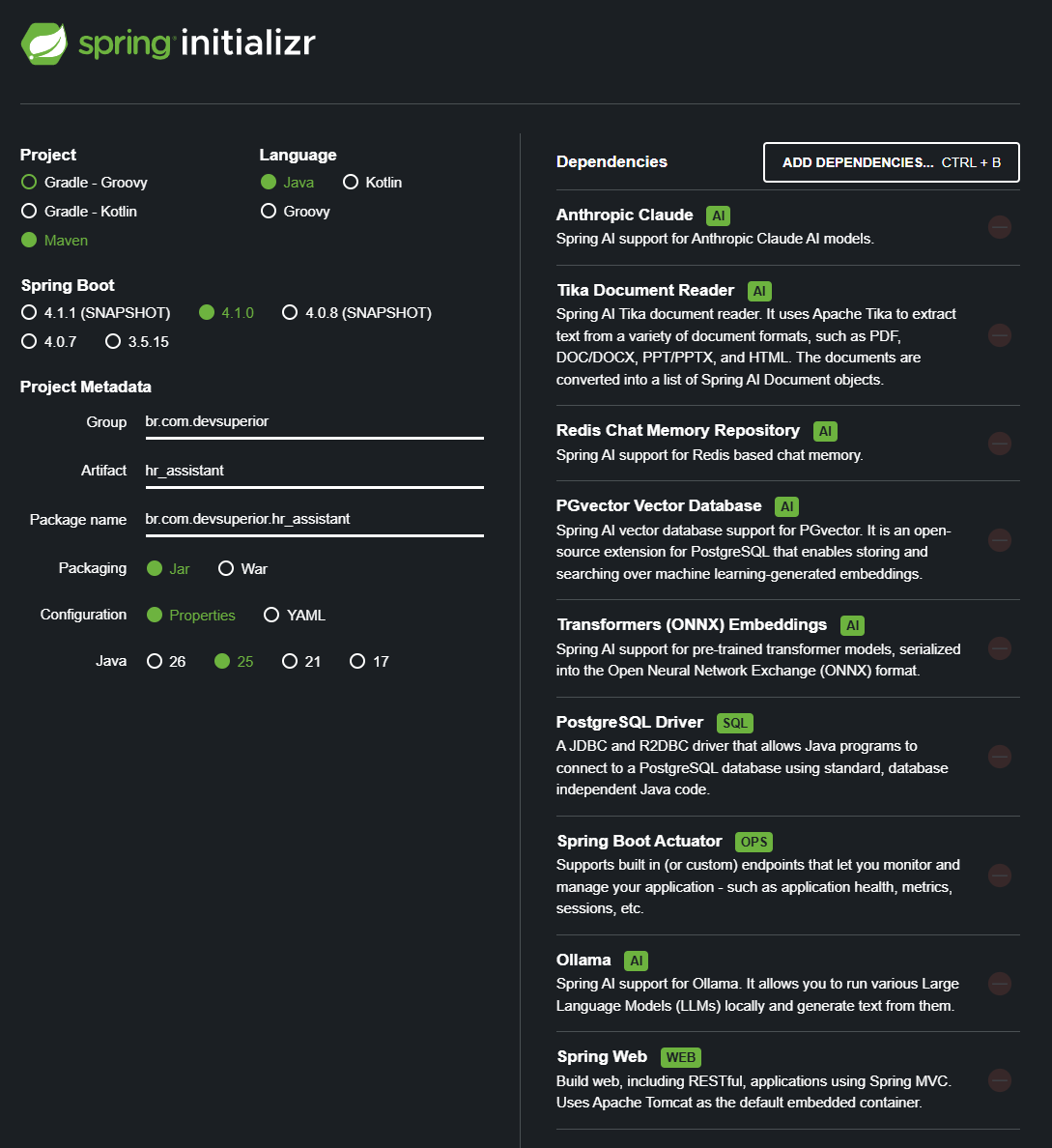 dependências e metadados a selecionar no Spring Initializr
dependências e metadados a selecionar no Spring Initializr
As dependências marcadas no Initializr são oito:
- Spring Web, para exposição dos endpoints.
- Spring Boot Actuator, para health checks e métricas.
- PostgreSQL Driver, o driver JDBC.
- Anthropic Claude, o starter de chat do Spring AI.
- Ollama, o starter dos embeddings locais.
- PGvector Vector Database, o vector store.
- Tika Document Reader, o leitor de PDF e outros formatos.
- Transformers (ONNX) Embeddings, alternativa de embedding 100% local, que deixamos disponível mas não usamos por padrão.
- Redis Chat Memory, é a memória em cache do contexto da conversa aberta.
Com o esqueleto pronto, vamos criar os artefatos nesta ordem. Cada um aparece em detalhe mais à frente. Você ainda pode clonar o projeto diretamente e acompanhar cada passo.
application.ymleapplication-anthropic.yml, a configuração de infraestrutura e do provedor.prompts/context-prompt.ste o PDF emresources/docs/, o template de grounding e a base de conhecimento.config/ChatClientConfig.java, o coração do projeto, monta oChatClient, a memória e os advisors.ingestion/IngestionService.javaeingestion/IngestionController.java, a pipeline que lê e indexa o PDF.chat/dto/ChatRequest.java,chat/ChatService.javaechat/ChatController.java, o fluxo de chat com streaming.chat/PromptLoggingAdvisor.java, a observabilidade do prompt.static/index.html, a interface de chat.docker-compose.yml, a infraestrutura.
A HrAssistantApplication (a classe main) já vem pronta do Initializr, não precisa criar. A estrutura final fica assim.
src/main/
├── java/br/com/devsuperior/hr_assistant/
│ ├── HrAssistantApplication.java
│ ├── config/ChatClientConfig.java # ChatClient, memoria e advisors
│ ├── ingestion/IngestionController.java # POST /ingest
│ ├── ingestion/IngestionService.java # le o PDF, divide e indexa
│ ├── chat/ChatController.java # POST /chat/stream (SSE)
│ ├── chat/ChatService.java # fala com o ChatClient
│ ├── chat/PromptLoggingAdvisor.java # loga o prompt final e a resposta
│ └── chat/dto/ChatRequest.java
└── resources/
├── application.yml # infra comum (Postgres, Redis, RAG)
├── application-anthropic.yml # profile do provedor (Claude + Ollama)
├── docs/aurora_car_dealer_politicas_rh.pdf
├── prompts/context-prompt.st # o template de grounding
└── static/index.html # a pagina de chatArquitetura
O sistema tem duas pipelines independentes. A ingestão roda uma vez, sob demanda. Ela recebe o PDF enviado no POST /ingest, quebra em pedaços, gera embeddings e grava no PgVector. O chat roda a cada mensagem do usuário. Ele recupera o histórico, busca trechos relevantes, chama o Claude e devolve a resposta em streaming.
Na ingestão, o TikaDocumentReader lê o arquivo. Ele usa o Apache Tika, que extrai texto de PDF, DOCX, PPTX, HTML e mais de cem formatos. Por ser genérico, é a escolha recomendada quando você quer aceitar vários tipos de documento sem trocar o código.
No fluxo de chat, os advisors fazem o trabalho pesado de forma transparente. Lembre da analogia, um advisor é como um interceptor do Spring MVC. Ele pode enriquecer a requisição antes de ela chegar ao modelo e tratar a resposta na volta, e roda em cadeia, numa ordem que você controla. No nosso caso, um advisor injeta o histórico da conversa, outro injeta os trechos do documento (RAG) e um terceiro loga tudo. Veja a sequência de uma única pergunta.
Detalhes Técnicos: a portabilidade por profiles
O ponto mais elegante do projeto é a portabilidade, uma assinatura clássica de projetos Spring. O código Java nunca conhece "Anthropic" nem "Ollama". Ele só fala com as abstrações ChatClient, EmbeddingModel e VectorStore. Quem decide o provedor são as properties, e nós separamos isso em dois arquivos.
O application.yml carrega a configuração comum de infraestrutura, que não muda quando você troca de modelo.
spring:
datasource:
url: jdbc:postgresql://localhost:5432/ragdb
username: postgres
password: postgres
ai:
vectorstore:
pgvector:
initialize-schema: true # cria a extensao, a tabela e o indice no primeiro start
index-type: HNSW # indice de busca aproximada de vizinhos
distance-type: COSINE_DISTANCE # distancia que casa com embeddings de sentenca
table-name: vector_store
chat:
memory:
redis:
host: localhost
port: 6379
time-to-live: PT30M # a conversa expira apos 30 min de inatividade
# bloco proprio do projeto (nao e do framework)
app:
rag:
top-k: 5 # quantos chunks o QuestionAnswerAdvisor recupera
similarity-threshold: 0.4 # piso de similaridade do retrieval
memory:
max-messages: 20 # tamanho da janela do MessageWindowChatMemory
# nivel DEBUG so para o advisor de observabilidade (PromptLoggingAdvisor)
logging:
level:
br.com.devsuperior.hr_assistant.chat.PromptLoggingAdvisor: DEBUGO initialize-schema: true faz o Spring AI criar a tabela vector_store e o índice HNSW sozinho no primeiro start, então você não escreve uma linha de SQL. O bloco app é nosso, não é do framework, e centraliza os números que vamos injetar no código mais à frente.
A configuração do provedor mora num profile, o application-anthropic.yml. O Spring Boot só carrega esse arquivo quando o profile anthropic está ativo.
spring:
ai:
model:
chat: anthropic
embedding: ollama # embedding sempre no Ollama, mesmo com chat na nuvem
anthropic:
api-key: ${ANTHROPIC_API_KEY}
chat:
model: claude-haiku-4-5
max-tokens: 1024
temperature: 0.1
ollama:
base-url: http://localhost:11435 # porta do container Ollama no compose
embedding:
model: bge-m3
vectorstore:
pgvector:
dimensions: 1024 # casa com a saida do bge-m3A porta 11435 no base-url é o mapeamento que o docker-compose expõe no host.
Quer rodar o chat 100% local, sem custo de nuvem? Crie um application-ollama.yml apontando spring.ai.model.chat para o Ollama com um modelo como gemma4:12b e ative o profile ollama. Quer experimentar outro provedor? Crie um application-openai.yml. O código Java não muda uma vírgula. Só lembre que o embedding (Ollama bge-m3) e a dimensions são os mesmos em qualquer profile, então leve esse bloco junto para o novo profile (ou suba-o para o application.yml comum).
Repare que o embedding é sempre o mesmo, o bge-m3 servido pelo Ollama, e só o provedor de chat muda. Neste artigo usamos o Claude na nuvem, que é o caminho mais reproduzível para acompanhar.
A escolha do bge-m3 não é à toa. Ele é multilíngue de ponta, com português excelente, gera vetores de 1024 dimensões e não exige prefixo nas consultas. Como o manual da Aurora é todo em PT-BR, isso pesa mais que o tamanho do vetor, muitos modelos focados em inglês medem similaridade em português de forma pobre. Fica só o acoplamento crítico de sempre, a dimensão do PgVector (dimensions: 1024) precisa casar com a do embedding. Trocou o modelo, ajuste a dimensão e faça novamente a ingestão o PDF, senão a busca quebra.
ℹ️ Como ativar o profile? A forma canônica e mais reproduzível é a flag na linha de comando,
./mvnw spring-boot:run -Dspring-boot.run.profiles=anthropic(é a que usamos na seção de Execução). Se você desenvolve no VS Code, dá para ativar pelo arquivo.env(SPRING_PROFILES_ACTIVE=anthropic) carregado nolaunch.jsonviaenvFile.
Implementação
ℹ️ Para focar no que importa, os trechos de código a seguir omitem
packagee, na maioria, osimport, mas você encontra eles completos no repositório do projeto.
A persona, o coração e a memória
Antes do código, um conceito que usamos bastante. A persona é o papel que damos ao assistente pelo system prompt, a mensagem inicial que define quem ele é, como deve falar e o que pode ou não fazer. O modelo carrega essas regras por toda a conversa. No projeto, a persona é uma constante de texto bem estruturada.
private static final String SYSTEM_PROMPT = """
# Papel
Você é o assistente virtual de RH da Aurora Car Dealer, uma concessionária
de veículos. Seu público são os colaboradores da empresa.
# Tom e estilo
- Responda sempre em português do Brasil.
- Seja objetivo, cordial e acolhedor, como um analista de RH experiente.
- Use frases curtas e, quando útil, listas para facilitar a leitura.
# Escopo
- Responda apenas dúvidas sobre políticas internas, benefícios, conduta e
procedimentos de RH da Aurora.
- Se a pergunta for claramente fora desse escopo, explique gentilmente que
você só trata de assuntos de RH e oriente o canal adequado.
# Regras de confiabilidade
- Baseie-se estritamente nas informações de RH fornecidas a você.
- Não invente políticas, valores, prazos ou contatos.
- Quando citar uma regra, indique a seção do manual que a embasou.
""";Repare que o SYSTEM_PROMPT cuida da persona, do tom e do escopo. A regra dura de responder apenas pelo contexto e a frase de fallback ficam em outro lugar, no template do RAG, que você vê adiante. O motivo é direto, a instrução de grounding (ancoramento) precisa morar ao lado do contexto que ela governa, e quem injeta esse contexto é o advisor, não o system prompt.
O coração está no ChatClientConfig. Ele leva @Configuration e reúne os parâmetros externalizados no application.yml, injetados com @Value.
import java.time.Duration;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.vectorstore.QuestionAnswerAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.chat.memory.repository.redis.RedisChatMemoryRepository;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import redis.clients.jedis.RedisClient;
@Configuration
public class ChatClientConfig {
@Value("${app.memory.max-messages}") int maxMessages;
@Value("${app.rag.top-k}") int topK;
@Value("${app.rag.similarity-threshold}") double similarityThreshold;
// infraestrutura do Redis, com valores padrao
@Value("${spring.ai.chat.memory.redis.host:localhost}") String redisHost;
@Value("${spring.ai.chat.memory.redis.port:6379}") int redisPort;
@Value("${spring.ai.chat.memory.redis.time-to-live:PT30M}") Duration redisTimeToLive; // ISO-8601 (PT30M), evite o formato 30m
// ... os beans abaixo entram aqui
}Com os campos no lugar, montamos a memória de conversa. O RedisChatMemoryRepository persiste as mensagens no Redis, e o MessageWindowChatMemory mantém uma janela das últimas mensagens.
⚠️ O
RedisClientusado aqui é o do Jedis (import redis.clients.jedis.RedisClient;), não o do Lettuce. Se a IDE auto-importar o nome errado, o.jedisClient(...)não compila.
@Bean
RedisChatMemoryRepository redisChatMemoryRepository() {
return RedisChatMemoryRepository.builder()
.jedisClient(RedisClient.create(redisHost, redisPort))
.initializeSchema(true)
.timeToLive(redisTimeToLive)
.build();
}
@Bean
ChatMemory chatMemory(RedisChatMemoryRepository repository) {
return MessageWindowChatMemory.builder()
.chatMemoryRepository(repository)
.maxMessages(maxMessages) // app.memory.max-messages
.build();
}Definimos o RedisChatMemoryRepository como bean manual de propósito, para controlar TTL, host e porta pelas nossas properties.
Agora o ChatClient. Montamos ele com o system prompt da persona e três advisors, nesta ordem, que importa.
MessageChatMemoryAdvisor, injeta o histórico da conversa como mensagens.QuestionAnswerAdvisor, faz o RAG, recuperando os trechos mais relevantes acima do piso de similaridade.PromptLoggingAdvisor, loga o prompt final e a resposta, comorderalto para rodar por último.
@Bean
ChatClient chatClient(ChatClient.Builder builder, ChatMemory chatMemory,
VectorStore vectorStore,
@Value("classpath:/prompts/context-prompt.st") Resource contextPrompt) {
PromptTemplate contextPromptTemplate = PromptTemplate.builder().resource(contextPrompt).build();
return builder
.defaultSystem(SYSTEM_PROMPT) // so a persona, o tom e o escopo
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory).build(),
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder()
.topK(topK).similarityThreshold(similarityThreshold).build())
.promptTemplate(contextPromptTemplate)
.build(),
new PromptLoggingAdvisor(1000)) // order alto, roda depois do RAG
.build();
}A ordem importa porque os advisors rodam em cadeia, e quem tem order menor roda antes. O MessageChatMemoryAdvisor tem order bem baixo (negativo), então entra primeiro e coloca o histórico na conversa, e o QuestionAnswerAdvisor (order padrão 0) já encontra esse histórico montado quando faz a busca. No fim, a pergunta chega ao Claude com três camadas combinadas, a persona do defaultSystem, o histórico da memória e os trechos do documento vindos do RAG.
Repare na divisão. No Spring AI, o modelo, a API key e a temperatura são configuração do provedor e ficam no application-anthropic.yml. Já a composição dos advisors, quais entram, em que ordem e com quais parâmetros, é montada em Java, porque o Spring AI não autoconfigura o conteúdo da cadeia por properties. Para não espalhar números mágicos pelo código, externalizamos esses valores no bloco app do application.yml e os injetamos com os mesmos @Value que você viu no topo da classe (topK, similarityThreshold e maxMessages).
Três detalhes importantes da memória. O MessageChatMemoryAdvisor injeta o histórico como mensagens estruturadas de usuário e assistente, que é a forma que o Claude entende melhor. Ele cuida dos dois lados do ciclo, antes da chamada lê o histórico do Redis, e ao final grava de volta a pergunta e a resposta, mesmo no streaming. Por fim, o conversationId é obrigatório em toda chamada, é ele que isola a conversa de cada usuário no Redis.
O template de grounding (anconragem/fundamentação)
A regra de ouro do grounding vive em um arquivo de template, o context-prompt.st. A extensão .st é de StringTemplate, a engine que o Spring AI usa por baixo dos panos. Em vez de concatenar texto em Java, você escreve o prompt num arquivo e deixa marcadores entre chaves para o framework preencher.
O QuestionAnswerAdvisor preenche dois marcadores obrigatórios:
{question_answer_context}, os trechos do manual que o RAG recuperou do PgVector.{query}, a pergunta original do colaborador.
É no arquivo, e não no código Java, que mora a instrução anti-alucinação. Como o QuestionAnswerAdvisor não recusa sozinho quando o contexto vem vazio, a frase de fallback precisa estar escrita no próprio template.
Vale separar dois casos, porque eles acionam mecanismos diferentes. Quando o retrieval não traz nenhum trecho acima do similarity-threshold, o contexto vai vazio e é essa frase do template que segura a resposta. Quando vêm trechos, mas a pergunta é claramente fora de escopo, quem atua é a persona do system prompt, que orienta ao canal certo. Por isso o assistente nem sempre devolve a frase literal, como você vai ver no teste do Wi-Fi.
Você está respondendo a uma pergunta de um colaborador da Aurora Car Dealer.
Use EXCLUSIVAMENTE o contexto abaixo, que contém trechos oficiais do manual de
políticas de RH da Aurora. O contexto está delimitado entre as marcas
CONTEXTO_INICIO e CONTEXTO_FIM.
CONTEXTO_INICIO
{question_answer_context}
CONTEXTO_FIM
Instruções:
1. Responda usando somente as informações dentro do contexto acima.
2. Se o contexto não contiver a informação, NÃO invente e responda exatamente:
"Não encontrei essa informação nas políticas oficiais da Aurora. Procure o RH
da sua unidade: rh@auroracardealerbr.com.br ou (31) 3200-1500, ramal 200."
3. Se a pergunta for sobre assédio ou denúncia, oriente o Canal de Ética:
0800-123-4567 / etica@auroracardealerbr.com.br.
4. Sempre que o trecho permitir, cite a seção do manual de onde veio a informação.
Pergunta do colaborador:
{query}A ingestão
A ingestão é uma pipeline ETL enxuta. O IngestionService recebe o PDF como um Resource, quebra em chunks e grava no vector store.
@Service
public class IngestionService {
private final VectorStore vectorStore;
public IngestionService(VectorStore vectorStore) { this.vectorStore = vectorStore; }
public int ingest(Resource pdf) {
List<Document> documents = new TikaDocumentReader(pdf).read();
List<Document> chunks = TokenTextSplitter.builder().build().apply(documents);
vectorStore.add(chunks);
return chunks.size();
}
}ℹ️ Chunk é um pedaço do documento. Quebramos o PDF em pedaços menores porque o modelo de embedding tem limite de tokens e porque a busca por similaridade fica mais precisa em trechos curtos do que no documento inteiro. O
TokenTextSplitterjá vem com tamanhos padrão que podem ser customizados.
Repare que não geramos embeddings em lugar nenhum à mão. Quando você chama vectorStore.add(chunks), o PgVectorStore usa o EmbeddingModel autoconfigurado para transformar cada chunk em vetor antes de gravar. Mais tarde, a cada pergunta, o mesmo EmbeddingModel vetoriza a pergunta para a busca. É o mesmo modelo nas duas pontas, por isso a dimensão da tabela precisa casar com a do modelo.
⚠️ O
vectorStore.addacrescenta, não substitui. Rodar oPOST /ingestduas vezes duplica os chunks. Ao reindexar o documento, limpe a tabela antes."`.
Quem dispara isso é o IngestionController, com um endpoint que recebe o PDF como upload. Como a aplicação é Spring MVC, o upload chega num MultipartFile, o tipo padrão da stack servlet.
@RestController
public class IngestionController {
private final IngestionService ingestionService;
public IngestionController(IngestionService ingestionService) { this.ingestionService = ingestionService; }
@PostMapping(value = "/ingest", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public Map<String, Integer> ingest(@RequestParam("file") MultipartFile file) {
return Map.of("chunksStored", ingestionService.ingest(file.getResource()));
}
}O chat com streaming
O corpo das mensagens é um record de uma linha, public record ChatRequest(String message) {}. O ChatService chama o ChatClient e devolve a resposta em streaming. No Spring AI, stream().content() devolve um Flux<String>.
@Service
public class ChatService {
private final ChatClient chatClient;
public ChatService(ChatClient chatClient) { this.chatClient = chatClient; }
public Flux<String> stream(String message, String conversationId) {
return chatClient.prompt()
.user(message)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, conversationId))
.stream()
.content();
}
}ℹ️ Um
Flux<String>é um fluxo assíncrono que entrega vários pedaços ao longo do tempo, em vez de umaStringpronta de uma vez. É o que faz a resposta surgir token a token.
O ChatController expõe esse fluxo. Este é um controller Spring MVC comum, ele retorna o próprio Flux com produces igual a TEXT_EVENT_STREAM_VALUE, e o MVC se encarrega de escrever cada item como um evento SSE, usando o processamento assíncrono do servlet. Por baixo, o Spring MVC reconhece o tipo reativo retornado e o adapta a um emitter assíncrono (na linha do ResponseBodyEmitter), escrevendo cada item conforme ele chega (similar ao que vemos em chats de IA), sem prender a thread. Ou seja, o Flux vem pronto do Spring AI e o MVC apenas o serializa pedaço a pedaço. Na prática, cada item do Flux sai como uma linha data:<token> no stream SSE, e é justamente esse prefixo data: que o front-end filtra na leitura. O conversationId chega pelo header que o front sempre envia, e ele é obrigatório, é o que agrupa uma conversa de um funcionário.
@RestController
public class ChatController {
private final ChatService chatService;
public ChatController(ChatService chatService) { this.chatService = chatService; }
@PostMapping(value = "/chat/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> stream(@RequestBody ChatRequest request,
@RequestHeader("X-Conversation-Id") String conversationId) {
return chatService.stream(request.message(), conversationId);
}
}Se você não precisasse de streaming, bastaria trocar .stream().content() por .call().content(), que devolve a resposta inteira de uma vez como String. Como queremos a resposta surgindo token a token, ficamos com o Flux servido como SSE.
Observabilidade: vendo o prompt exato que vai ao Claude
Com tanta coisa sendo injetada por baixo dos panos (persona, histórico, contexto do RAG), como você tem certeza do que realmente chega ao modelo? A resposta é um advisor de observabilidade.
O PromptLoggingAdvisor é um advisor customizado. Ele implementa BaseAdvisor e loga, em nível DEBUG, o prompt completo na ida e a resposta na volta. O pulo do gato é o order, ao usar um valor alto (1000), ele roda depois do QuestionAnswerAdvisor (order 0), então enxerga o prompt já enriquecido, com o contexto do RAG dentro.
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.chat.client.ChatClientMessageAggregator;
import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.AdvisorChain;
import org.springframework.ai.chat.client.advisor.api.BaseAdvisor;
import org.springframework.ai.chat.client.advisor.api.StreamAdvisorChain;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.Message;
import reactor.core.publisher.Flux;
public class PromptLoggingAdvisor implements BaseAdvisor {
private static final Logger logger = LoggerFactory.getLogger(PromptLoggingAdvisor.class);
private final int order;
public PromptLoggingAdvisor(int order) { this.order = order; }
@Override
public Flux<ChatClientResponse> adviseStream(ChatClientRequest request, StreamAdvisorChain chain) {
logPrompt(request); // IDA: o prompt ja aumentado
Flux<ChatClientResponse> responses = chain.nextStream(request);
// agrega os tokens do stream e loga a resposta completa uma unica vez
return new ChatClientMessageAggregator()
.aggregateChatClientResponse(responses, r -> logResponse(request, r));
}
@Override public int getOrder() { return order; }
// before/after sao exigidos por BaseAdvisor; aqui so repassam sem alterar
@Override public ChatClientRequest before(ChatClientRequest req, AdvisorChain chain) { return req; }
@Override public ChatClientResponse after(ChatClientResponse res, AdvisorChain chain) { return res; }
private void logPrompt(ChatClientRequest request) {
if (!logger.isDebugEnabled()) return;
Object conversationId = request.context().get(ChatMemory.CONVERSATION_ID);
StringBuilder prompt = new StringBuilder();
for (Message m : request.prompt().getInstructions()) // percorre SYSTEM, USER, etc.
prompt.append("\n┌── ").append(m.getMessageType()).append(" ──\n").append(m.getText());
logger.debug("📤 IDA — Prompt enviado ao modelo [conversationId={}]{}", conversationId, prompt);
}
private void logResponse(ChatClientRequest request, ChatClientResponse response) {
if (!logger.isDebugEnabled()) return;
Object conversationId = request.context().get(ChatMemory.CONVERSATION_ID);
String answer = response.chatResponse().getResult().getOutput().getText();
logger.debug("📥 VOLTA — Resposta gerada pelo modelo [conversationId={}]\n{}", conversationId, answer);
}
}Note o detalhe do streaming. A resposta chega token a token, e logar cada pedaço não seria nada útil. Por isso usamos o ChatClientMessageAggregator, que junta os tokens do Flux e nos entrega a resposta inteira para logar uma única vez no fim. Os métodos before e after, exigidos pelo BaseAdvisor, cobrem o caminho síncrono (quando você usa .call() em vez de .stream()), que não usamos aqui, por isso só repassam o objeto.
Com logging.level em DEBUG para esse advisor no application.yml, ao perguntar "quantos dias de licença-paternidade eu tenho?" o console mostra exatamente o que o RAG montou.
📤 IDA — Prompt enviado ao modelo [conversationId=59d8...]
┌── SYSTEM ──
# Papel
Você é o assistente virtual de RH da Aurora Car Dealer...
┌── USER ──
Use EXCLUSIVAMENTE o contexto abaixo...
CONTEXTO_INICIO
LICENÇA-PATERNIDADE:
• 20 dias a partir do nascimento do filho, conforme Programa Empresa Cidadã
• O colaborador deve comunicar o nascimento ao RH em até 5 dias úteis...
CONTEXTO_FIM
Pergunta do colaborador:
Quantos dias de licença-paternidade eu tenho?
📥 VOLTA — Resposta gerada pelo modelo [conversationId=59d8...]
Você tem direito a 20 dias de licença-paternidade a partir do nascimento do
filho, conforme o Programa Empresa Cidadã... (seção 4.2 do Manual).Esse log é ouro para depurar RAG. Resposta estranha? Olhe o bloco CONTEXTO_INICIO. Se o trecho certo não foi recuperado, o problema está no retrieval (ajuste top-k ou similarity-threshold), não no modelo. Você para de adivinhar e passa a enxergar.
Dois ajustes andam juntos aqui. Cada chunk recuperado entra no prompt e conta como token de entrada enviado ao Claude, então um top-k alto encarece e ainda polui o contexto com trecho irrelevante. Já um similarity-threshold alto demais pode zerar o retrieval e jogar o assistente no fallback mesmo existindo a resposta no manual, que é justamente o sintoma que esse log denuncia na hora.
O front-end
No index.html, um JavaScript puro consome o stream com fetch e ReadableStream, gerando um conversationId em localStorage que vai no header X-Conversation-Id. O ponto técnico interessante é o parser de SSE. O servidor envia cada evento como linhas que começam com data:, separadas por uma linha em branco, e um pedaço do ReadableStream pode chegar partido no meio de um evento. Por isso usamos um buffer.
const res = await fetch("/chat/stream", {
method: "POST",
headers: { "Content-Type": "application/json",
"X-Conversation-Id": getConversationId() },
body: JSON.stringify({ message })
});
const reader = res.body.getReader();
const decoder = new TextDecoder();
let sseBuffer = "", botText = "";
while (true) {
const { value, done } = await reader.read();
if (done) break;
sseBuffer += decoder.decode(value, { stream: true });
// fecha um evento a cada linha em branco ("\n\n")
let sep;
while ((sep = sseBuffer.indexOf("\n\n")) !== -1) {
const rawEvent = sseBuffer.slice(0, sep);
sseBuffer = sseBuffer.slice(sep + 2);
for (const line of rawEvent.split("\n"))
if (line.startsWith("data:")) botText += line.slice(5);
}
output.innerHTML = renderMarkdown(botText); // re-renderiza a cada chunk
}O trecho acima é só o núcleo do streaming, o message vem do input do formulário e output é o elemento onde renderizamos a resposta, a página completa (com o HTML e um renderizador de markdown simples) está no repositório. Para um teste local, ele entrega a experiência de resposta surgindo aos poucos, igual aos assistentes que você já usa.
Execução e Testes
A infraestrutura sobe via Docker. O docker-compose.yml define o Postgres com PgVector, o Redis Stack e o Ollama que serve o bge-m3. Importante, a infra roda no Docker e a aplicação roda no host (via mvnw), por isso todas as properties apontam para localhost.
services:
db:
image: pgvector/pgvector:pg18
environment:
POSTGRES_DB: ragdb
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
ports: ["5432:5432"]
volumes: ["pgdata:/var/lib/postgresql"] # pg18: o PGDATA fica em /18/...; o volume no diretorio pai persiste tudo
redis:
image: redis/redis-stack:latest # precisa ser redis-stack (modulos JSON/search), nao o redis comum
ports: ["6379:6379", "8001:8001"] # 8001 e o RedisInsight, painel web
volumes: ["redisdata:/data"]
ollama:
image: ollama/ollama:latest
ports: ["11435:11434"]
volumes: ["ollama:/root/.ollama"]
entrypoint: ["/bin/sh", "-c"]
command:
- |
ollama serve &
pid=$$!
until ollama list >/dev/null 2>&1; do sleep 1; done
ollama pull bge-m3
wait $$pid
healthcheck: # so fica saudavel quando o bge-m3 ja esta disponivel
test: ["CMD-SHELL", "ollama list 2>/dev/null | grep -q bge-m3 || exit 1"]
interval: 10s
start_period: 60s
volumes:
pgdata:
redisdata:
ollama:Usamos o redis/redis-stack para a memória de chat do Spring AI. O serviço ollama sobe o servidor, espera ficar pronto, baixa o bge-m3 e segue servindo. Atenção ao bloco command: - |, a indentação dele é significativa, copie o YAML preservando os espaços. O healthcheck só fica verde quando o modelo já está no ar, o que evita uma corrida na hora da ingestão. Suba tudo com um comando.
docker compose up -dO bge-m3 é um modelo de embedding open source multilíngue (100+ idiomas) desenvolvido pela BAAI (Beijing Academy of Artificial Intelligence) que unifica três tipos de recuperação, densa, esparsa e multi-vetor, em um único modelo, com suporte a textos de até 8.192 tokens.
Na primeira vez, o bge-m3 (cerca de 1,2 GB) é baixado uma única vez e fica guardado no volume ollama, o que pode levar alguns minutos, então as próximas subidas são instantâneas. Antes de seguir, rode docker compose ps e confirme os três serviços de pé, esperando o Ollama aparecer como healthy (ou use docker compose logs -f ollama até ver o bge-m3 pronto). Subir a aplicação ou ingerir antes disso falha com erro de conexão. Com a infraestrutura no ar, defina a chave da Anthropic e suba a aplicação com o profile anthropic.
export ANTHROPIC_API_KEY="sua-chave-aqui"
./mvnw spring-boot:run -Dspring-boot.run.profiles=anthropicNo Windows com PowerShell, troque o export por $env:, no formato $env:ANTHROPIC_API_KEY="sua-chave".
💡 No Windows, rode os comandos
curle os loops de shell deste artigo pelo Git Bash (ou WSL). No PowerShell puro, ocurlde ingestão precisa ficar em uma única linha (sem a\de quebra) e o loopwhiledo teste de memória não funciona.
Com a aplicação no ar abra outro termina, dispare a ingestão uma vez, enviando o PDF. O PDF de exemplo já vem no repositório em src/main/resources/docs/, então se você está construindo do zero, baixe-o de lá ou use qualquer PDF de políticas, e rode o curl a partir da raiz do projeto. A resposta confirma quantos chunks foram indexados.
curl -X POST -F "file=@src/main/resources/docs/aurora_car_dealer_politicas_rh.pdf" \
http://localhost:8080/ingest
# {"chunksStored":16} (o numero varia conforme o PDF)💡 No Windows, rode esse
curlem uma única linha (sem a quebra) ou use o Git Bash.
Agora a parte boa. Abra o navegador em http://localhost:8080 e pergunte algo coberto pelo manual, como a licença-paternidade. A resposta aparece token a token e vem ancorada, citando inclusive a seção do manual.
 o assistente responde sobre licença-paternidade citando a seção 4.2 e o contato do RH
o assistente responde sobre licença-paternidade citando a seção 4.2 e o contato do RH
Nos bastidores, o assistente gerou o embedding da pergunta, buscou os trechos mais parecidos no PgVector, injetou tudo no prompt e o Claude respondeu ancorado, exatamente o que vimos no log de observabilidade.
Agora o teste que separa um brinquedo de uma ferramenta séria. Pergunte algo que não está no documento, como a senha do Wi-Fi de visitantes.
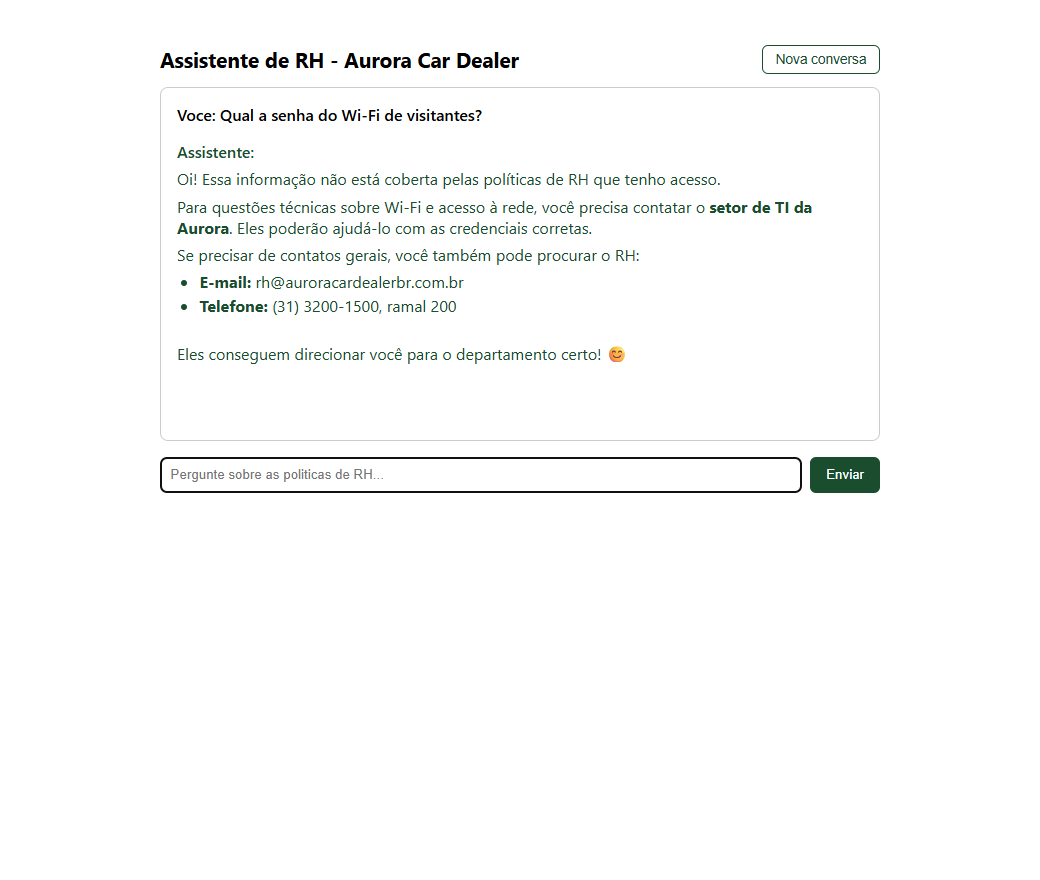 pergunta fora do escopo, o assistente não inventa e direciona ao canal certo
pergunta fora do escopo, o assistente não inventa e direciona ao canal certo
Em vez de chutar uma senha, ele reconhece que a informação não está nas políticas de RH e direciona ao setor adequado, oferecendo o contato do RH.
ℹ️ Repare que a resposta não é a frase literal do template. Aqui aparece um ponto importante sobre LLMs, a frase de fallback no
context-prompt.sté o piso de segurança para quando o retrieval volta vazio, mas a persona do system prompt também orienta saídas fora de escopo. Ele não inventa e encaminha a um humano.
Falta provar a memória de conversa. Como o histórico é isolado pelo conversationId, dá para conversar pelo terminal reaproveitando o mesmo id em cada chamada.
CID="sessao-terminal-1"
while true; do
read -p "voce: " MSG
curl -N -s -X POST http://localhost:8080/chat/stream \
-H "Content-Type: application/json" \
-H "X-Conversation-Id: $CID" \
-d '{"message": "'"$MSG"'"}'
echo
doneEvite acentuação no terminal (mas você pode testar via front no http://localhost:8080/) e pergunte sobre "qual a licenca paternidade?" e, na sequência, mande só "e de maternidade?" em seguida "o que foi que te perguntei?". Ele entende que você continua falando de licenças, porque o histórico da sessão entra no contexto. Esse é o papel da memória que configuramos no Redis. Como esse histórico vive no Redis com TTL de 30 minutos, reusar o mesmo conversationId depois de reiniciar a aplicação ainda traz a conversa anterior, limpe pelo RedisInsight se quiser recomeçar do zero. Quer ver por dentro? Os chunks indexados ficam na tabela vector_store do Postgres, e o histórico das sessões aparece no RedisInsight em http://localhost:8001.
⚠️ Se algo der errado, comece por aqui:
- Erro de autenticação (401) da Anthropic, a
ANTHROPIC_API_KEYnão foi exportada no mesmo terminal domvnw, ou a conta está sem créditos.- O chat responde como se nada estivesse indexado, o profile
anthropicprovavelmente não está ativo (rode com-Dspring-boot.run.profiles=anthropic) ou a ingestão não rodou.- Erro ao inserir ou buscar no PgVector, a dimensão da tabela não casa com o embedding, confirme
dimensions: 1024e reingira numa tabela limpa.- Erro de conexão com o Ollama na ingestão, o
bge-m3ainda não terminou de baixar, espere o healthcheck ficarhealthy.
Conclusão
Construímos um assistente de RH que responde pela fonte oficial, não inventa e sabe a hora de passar a bola para um humano. No caminho, você viu RAG de verdade com PgVector, streaming via SSE servido pelo Spring MVC, memória de conversa no Redis, observabilidade do prompt com um advisor customizado e, talvez o mais valioso, a troca de provedor de chat por profile, sem tocar no código Java.
Esse é o superpoder do Spring AI. Ele torna a IA generativa provider-agnostic e acessível a qualquer desenvolvedor que já conhece Spring. A barreira de entrada para construir produtos de IA caiu, e quem aprende isso agora vai estar exatamente onde as empresas estão investindo.
O código completo está no repositório github.com/devsuperior/blog.
Agora pega seu token da Anthropic e bora codar. Bons estudos e até a próxima.