Um sistema event-driven em produção convive com falhas externas. Basta uma integração do consumer oscilar por alguns minutos, e ele começará a reprocessar a mesma mensagem em loop, a fila acumula silenciosamente e uma mensagem problemática pode travar o sistema inteiro. O cenário é comum e tem solução dentro do próprio SQS, sem orquestração externa e implementação artesanal de reprocessamento.
Neste artigo vamos configurar DLQ + Retentativas, dimensionar Visibility Timeout com critério, fazer redrive manual depois de consertar a causa raiz, e olhar as métricas certas que avisam antes do estrago. Tudo rodando local em LocalStack, com microsserviços Spring Boot 4 escritos em Java 25.
ℹ️ Este conteúdo é o Episódio 3 de 3 da série Dominando Mensageria na AWS. No Episódio 1 implementamos o padrão Point-to-Point com SQS. No Episódio 2 evoluímos para Pub/Sub com SNS + SQS. Aqui fechamos a série com resiliência sob falha.
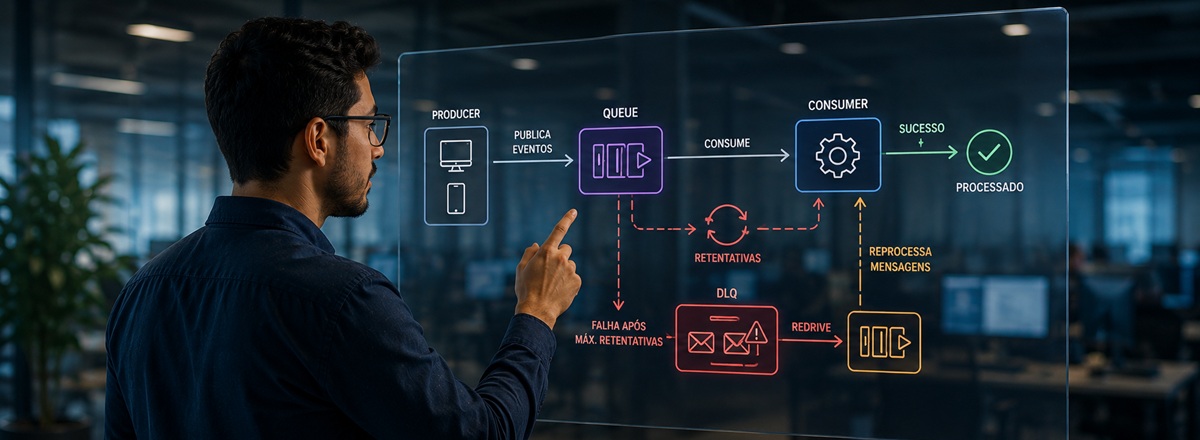
O ciclo de vida de uma mensagem SQS
Antes de falar de DLQ, vale revisitar o que acontece com uma mensagem desde que entra na fila até sumir de vez. O desenho é simples:
Quando o consumer pega a mensagem via ReceiveMessage, ela não some imediatamente. Entra em estado inflight, invisível para outros consumers durante o Visibility Timeout (padrão de 30s). Se o processamento termina sem exceção, o framework chama DeleteMessage e a mensagem desaparece. Se falha, o Visibility Timeout (VT) expira e a mensagem volta a ficar visível.
E aí mora a primeira armadilha. Se o VisibilityTimeout é curto demais, uma mensagem ainda sendo processada volta a ficar visível e outro consumer pega ela em paralelo, dobrando o trabalho. A recomendação oficial da AWS é deixar o VT igual ou maior que o tempo máximo típico de processamento. Se você ainda não conhece esse tempo, comece com o valor conservador que a própria AWS sugere (2 minutos) e ajuste depois. Para processamentos longos ou de duração variável, use o ChangeMessageVisibility como heartbeat, o consumer estende o VT enquanto continua trabalhando. Cuidado com o excesso para o outro lado também, VT muito alto atrasa a retentativa de mensagens que falharam.
💡 Detalhe que evita dor de cabeça: o SQS expõe um header chamado
ApproximateReceiveCountem cada mensagem, contando quantas vezes ela já foi tentada. É a partir dele que toda a lógica de retry e DLQ funciona.
RedrivePolicy e o nascimento da DLQ
Uma Dead Letter Queue (fila morta), apesar do nome dramático, é um SQS comum. O que a torna "morta" é o papel de destino: ela é apontada por outra fila como o lugar onde mensagens que falharam demais vão parar.
A magia está num atributo da fila principal chamado RedrivePolicy, com dois campos:
deadLetterTargetArn, ARN da fila que vai receber as falhas.maxReceiveCount, número máximo de tentativas antes de mover.
Quando o ApproximateReceiveCount bate em maxReceiveCount, o próprio SQS move a mensagem para a DLQ, sem nenhuma linha de código no consumer. Você não orquestra retentativa, não move mensagem na mão, não escreve handler para detectar "tentei demais". O SQS faz sozinho.
Reforçando: a DLQ não é uma fila mágica, é uma SQS normal. O que muda é o propósito operacional. Mensagens lá significam "tentamos demais, alguém precisa olhar". O time recebe alarme, abre o conteúdo, identifica a causa raiz, e faz o redrive devolvendo as mensagens para a fila principal.
A AWS possui a API start-message-move-task, que faz o redrive nativamente, sem gerenciar offset, paralelismo ou idempotência na mão. Vamos usar isso aqui.
Falha transiente, falha permanente
Vale separar dois tipos de falha que aparecem em mensageria:
- Falha transiente, condição passageira que provavelmente vai passar com nova tentativa: gateway fora por minutos, throttling, timeout de rede, deadlock. Retentar faz sentido.
- Falha permanente (poison pill), payload malformado que sempre vai falhar. Retentar é desperdiçar
maxReceiveCount.
Este artigo cobre apenas falha transiente. Existe outro tipo de tratamento para poison pill que merece código dedicado e está fora do escopo aqui.
Atenção a um efeito colateral do FIFO: enquanto uma mensagem está em ciclo de retentativa, as mensagens seguintes do mesmo MessageGroupId ficam esperando (em outros grupos seguem normalmente). Por isso o maxReceiveCount precisa ser dimensionado com cuidado: muito baixo e perdemos mensagens para falhas transitórias rápidas, muito alto e travamos o grupo por minutos a fio.
Overview rápido do Projeto
Estamos trabalhando em um Sistema de Reserva de Ingressos.
Quando o show da artista X abre vendas, milhares de fãs disparam reservas em segundos. O sistema precisa garantir duas coisas que SNS + SQS Standard não dão por padrão:
- ordem por show (quem clicou primeiro no show X tem prioridade)
- deduplicação automática (se o front cliente reenviar a mesma
reservationIdpor timeout de rede, o sistema não cria duas reservas).
Para isso usamos SQS FIFO em High Throughput Mode:
- SQS FIFO, ordena mensagens dentro de um grupo (clientes vendo o show X recebem na ordem em que reservaram).
MessageGroupId=showId, cada show tem ordem própria, shows diferentes processam em paralelo (clientes de shows distintos não esperam uns aos outros).- High Throughput Mode (
DeduplicationScope=messageGroup+FifoThroughputLimit=perMessageGroupId), sobe o teto da fila para milhares de mensagens por segundo, muito acima dos 300 msg/s do FIFO padrão, com paralelismo entre grupos. Limites exatos variam por região, consulte os SQS Service Quotas. ContentBasedDeduplication=true, dedup automática quando o front reenvia a mesma reserva por timeout de rede (mesmo conteúdo = mesma mensagem dentro de 5 minutos).
Quem fez o episódio anterior reconhece tudo isso. Quem não fez, esse resumo já basta para acompanhar o restante.
O que a AWS recomenda
A própria AWS dedica bastante material a esse tema, vale conhecer as fontes primárias antes de partir para o hands-on. Três leituras compõem uma base sólida.
O post Using Amazon SQS Dead-Letter Queues to Control Message Failure no AWS Compute Blog é o ponto de partida clássico. Explica quando faz sentido usar DLQ, como configurar alarmes em cima dela e detalha as diferenças entre DLQ em filas padrão e FIFO, ponto importante para o nosso projeto que usa FIFO HT.
A página Capturing problematic messages in Amazon SQS no Developer Guide do SQS é leitura obrigatória sobre o efeito de poison pills na métrica ApproximateAgeOfOldestMessage. Sem DLQ, uma única mensagem problemática distorce o monitoramento de toda a fila, gerando alarme falso ou, pior, mascarando o problema real.
E o guia Amazon SQS Dead-Letter Queues consolida boas práticas, incluindo o detalhe importante de que o maxReceiveCount deve ser dimensionado em função do tempo total de retentativa aceitável para o consumer, não num número arbitrário. Para FIFO, o documento também alerta sobre o efeito no MessageGroupId, exatamente o ponto que abordamos na seção anterior.
A topologia que vamos montar abaixo aplica diretamente essas três recomendações: DLQ apontada via RedrivePolicy com maxReceiveCount calibrado, alarmes simples em duas métricas do CloudWatch e redrive via API nativa quando o time confirmar que a causa raiz foi resolvida.
Nosso Projeto
Pagamento mostrou fan-out. Agora vamos para um sistema com requisitos mais duros, reserva de ingressos, onde a falha de um consumer pode travar a venda do show inteiro. O fluxo:
ms-ticket-ingestor(8081), recebePOST /api/reservations, enfileira emreservation-queue.fifocomMessageGroupId=showId.ms-reservation-handler(8082), valida, calcula preço final com taxa, persiste no H2 com idempotência porreservationId, publicaReservationConfirmedEventno SNS topic FIFOticket-events.fifo.ms-notification(8083),SseEmitterporreservationIdpara confirmar a reserva em tempo real no navegador.ms-fulfillment(8084), chama um "gateway de impressão" fictício para liberar o QR code. Único consumer com DLQ, é onde a falha transiente vai acontecer.
💡 Decisão didática: apenas 1 DLQ, na
fulfillment-queue.fifo, onde a falha externa acontece. As outras filas ficam sem DLQ para manter o foco em um único cenário.
Mão na Massa
O projeto está disponível no repositório do blog. Stack:
- Java 25, Maven (via
mvnw), Spring Boot 4.0.5. - Spring Cloud AWS 4.0 (starters SQS e SNS).
- Spring Data JPA + H2 no reservation-handler, Spring Web com
SseEmitterno notification. - Docker com LocalStack emulando SQS e SNS.
Clone e entre na pasta:
git clone https://github.com/devsuperior/blog.git
cd blog/articles/mensageria-e-dlq-retentativas-e-redrive/projectsA estrutura é direta, cada microsserviço numa pasta dedicada:
articles/mensageria-e-dlq-retentativas-e-redrive/projects/
├── docker-compose.yml
├── init-scripts/
│ └── 01-create-topology.sh
├── ms-ticket-ingestor/ (porta 8081)
├── ms-reservation-handler/ (porta 8082)
├── ms-notification/ (porta 8083)
└── ms-fulfillment/ (porta 8084)💡 Windows? Use Git Bash para rodar os comandos deste guia (
grep,\quebra de linha,export VAR=valor, redirects). No PowerShell, a sintaxe seria$env:VAR = "valor", semgrepnativo (useSelect-String).
Subindo a infraestrutura local
⚠️ A partir de março de 2026, o LocalStack exige um
LOCALSTACK_AUTH_TOKEN. Crie conta gratuita em app.localstack.cloud, navegue para Auth Tokens no menu lateral, clique em Create, copie o valorls-...e exporte comoLOCALSTACK_AUTH_TOKENantes de subir o container. Detalhes no guia oficial.
O docker-compose.yml sobe o LocalStack habilitando SQS e SNS:
services:
localstack:
image: localstack/localstack:latest
container_name: localstack
ports:
- "4566:4566"
environment:
- SERVICES=sqs,sns
- LOCALSTACK_AUTH_TOKEN=${LOCALSTACK_AUTH_TOKEN}
- AWS_DEFAULT_REGION=us-east-1
volumes:
- "./init-scripts:/etc/localstack/init/ready.d"O script init-scripts/01-create-topology.sh cria toda a topologia: o topic SNS FIFO, as 3 filas FIFO HT principais + 1 DLQ FIFO, e assina as 2 subscriptions com RawMessageDelivery=true. O trecho central que configura o RedrivePolicy:
DLQ_ARN="arn:aws:sqs:us-east-1:000000000000:fulfillment-dlq.fifo"
awslocal sqs set-queue-attributes \
--queue-url http://localhost:4566/000000000000/fulfillment-queue.fifo \
--attributes "{\"RedrivePolicy\":\"{\\\"deadLetterTargetArn\\\":\\\"${DLQ_ARN}\\\",\\\"maxReceiveCount\\\":\\\"3\\\"}\"}"Lembrando: o RedrivePolicy vive na fila principal, não na DLQ. A DLQ não sabe que é DLQ, ela é só uma fila FIFO comum apontada pela outra.
Subindo a infra:
export LOCALSTACK_AUTH_TOKEN=ls-xxxxxxxxxxxxxxxxxxxxxxxx
docker compose up -d
docker logs -f localstack | grep -m1 "Topologia criada"Quando aparecer Topologia criada: 3 filas + 1 DLQ + 1 topic + 2 subscriptions, está pronto. Confira pelo host com o aws cli apontando para o endpoint do LocalStack:
# Credenciais dummy para o aws cli (o LocalStack aceita qualquer valor)
export AWS_SESSION_TOKEN=
export AWS_ACCESS_KEY_ID=test
export AWS_SECRET_ACCESS_KEY=test
aws --endpoint-url=http://localhost:4566 sqs list-queues --region us-east-1
aws --endpoint-url=http://localhost:4566 sns list-topics --region us-east-1Você verá 4 filas (reservation, notification, fulfillment, fulfillment-dlq) e 1 topic (ticket-events.fifo).
Enviando mensagem com MessageGroupId
No produtor (ms-ticket-ingestor), o SqsTemplate passa o MessageGroupId via header. Spring Cloud AWS 4.0 expõe a constante certa:
sqsTemplate.send(to -> to
.queue(reservationQueue)
.payload(request)
.header(SqsHeaders.MessageSystemAttributes.SQS_MESSAGE_GROUP_ID_HEADER, request.showId())
.header(SqsHeaders.MessageSystemAttributes.SQS_MESSAGE_DEDUPLICATION_ID_HEADER, request.reservationId()));Mesmo padrão no ms-reservation-handler quando publica no topic SNS, com SnsHeaders.MESSAGE_GROUP_ID_HEADER. Sem essas constantes o SDK reclama de FIFO queue exigindo MessageGroupId.
O errorHandler que loga ApproximateReceiveCount
No ms-fulfillment, a gente quer enxergar a tentativa crescer até bater no maxReceiveCount=3. Crie a classe com.devsuperior.fulfillment.config.SqsErrorHandlerConfig, anotada com @Configuration, expondo um bean defaultSqsListenerContainerFactory que sobrescreve o auto-configurado pelo Spring Cloud AWS:
@Configuration
public class SqsErrorHandlerConfig {
private static final Logger log = LoggerFactory.getLogger(SqsErrorHandlerConfig.class);
@Bean
public ErrorHandler<Object> approximateReceiveCountErrorHandler() {
return (message, throwable) -> {
String receiveCount = (String) message.getHeaders()
.get(SqsHeaders.MessageSystemAttributes.SQS_APPROXIMATE_RECEIVE_COUNT);
Throwable rootCause = throwable;
while (rootCause.getCause() != null && rootCause.getCause() != rootCause) {
rootCause = rootCause.getCause();
}
log.warn("Tentativa #{} de processar mensagem {} falhou: {}",
receiveCount, message.getHeaders().getId(), rootCause.getMessage());
if (throwable instanceof RuntimeException re) {
throw re;
}
throw new RuntimeException(throwable);
};
}
}O while faz unwrap até a causa raiz, evitando logs poluídos com AsyncAdapterBlockingExecutionFailedException envelopando a exceção real.
O FulfillmentService simula o gateway. Quando o profile gateway-down está ativo, app.fulfillment.gateway-down=true (via application-gateway-down.properties) e o serviço joga RuntimeException, exercitando o ciclo de retentativa:
public void releaseTickets(ReservationConfirmedEvent event) {
if (gatewayDown) {
throw new RuntimeException("Gateway de impressao indisponivel");
}
log.info("Liberando QR code para reserva {} (show {}, tier {})",
event.reservationId(), event.showId(), event.ticketTier());
}Subindo os microsserviços e fluxo feliz
Cada serviço em um terminal:
cd ms-ticket-ingestor && ./mvnw spring-boot:run
cd ms-reservation-handler && ./mvnw spring-boot:run
cd ms-notification && ./mvnw spring-boot:run
cd ms-fulfillment && ./mvnw spring-boot:runAbra um stream SSE em outro terminal para ver a confirmação chegar:
curl -N http://localhost:8083/api/notifications/stream/r-001Dispare a primeira reserva:
curl -X POST http://localhost:8081/api/reservations \
-H "Content-Type: application/json" \
-d '{
"reservationId": "r-001",
"showId": "show-coldplay-2026",
"ticketTier": "PISTA",
"quantity": 2,
"unitPriceUsd": 120.00,
"buyerEmail": "ana@example.com",
"requestedAt": "2026-05-27T18:00:00Z"
}'Você verá event:reservation-confirmed no SSE e Liberando QR code para reserva r-001 no log do fulfillment. Mande outra reserva no mesmo showId=show-coldplay-2026, depois uma terceira em show-rbd-2026, para ver ordem preservada por show e paralelismo entre shows.
Cenário: gateway downstream caiu
Hora de quebrar de propósito. Pare o ms-fulfillment (Ctrl+C) e reinicie com o profile gateway-down ativo:
cd ms-fulfillment
./mvnw spring-boot:run -Dspring-boot.run.profiles=gateway-downUsamos Spring Profile (e não variável de ambiente) para manter a configuração isolada no application-gateway-down.properties, sem precisar exportar variáveis entre shells diferentes (Git Bash, PowerShell, cmd).
Dispare nova reserva com reservationId=r-002. Os logs do ms-fulfillment mostram a tentativa subindo:
Tentativa #1 de processar mensagem ... falhou: Gateway de impressao indisponivel
Tentativa #2 de processar mensagem ... falhou: Gateway de impressao indisponivel
Tentativa #3 de processar mensagem ... falhou: Gateway de impressao indisponivelDepois da terceira, a mensagem some da fulfillment-queue.fifo e aparece na DLQ. Confirma:
aws --endpoint-url=http://localhost:4566 sqs get-queue-attributes \
--queue-url http://localhost:4566/000000000000/fulfillment-dlq.fifo \
--attribute-names ApproximateNumberOfMessages \
--region us-east-1Retorno: "ApproximateNumberOfMessages": "1". A reserva está segura na fila morta, esperando alguém olhar.
Redrive: voltando à vida depois do conserto
O time investigou e o gateway voltou. Pare o ms-fulfillment (Ctrl+C) e suba de novo sem o profile (default = gateway up):
cd ms-fulfillment
./mvnw spring-boot:runAntes de mover, vale espiar a mensagem que travou para confirmar o conteúdo:
aws --endpoint-url=http://localhost:4566 sqs receive-message \
--queue-url http://localhost:4566/000000000000/fulfillment-dlq.fifo \
--max-number-of-messages 1 \
--attribute-names ApproximateReceiveCount \
--region us-east-1O ApproximateReceiveCount=3 confirma que ela bateu no maxReceiveCount antes de cair aqui.
E dispare a task de redrive nativa:
aws --endpoint-url=http://localhost:4566 sqs start-message-move-task \
--source-arn arn:aws:sqs:us-east-1:000000000000:fulfillment-dlq.fifo \
--region us-east-1Em segundos, r-002 volta para a fulfillment-queue.fifo, é consumida, e o log final aparece: Liberando QR code para reserva r-002. A DLQ finalmente esvazia e normaliza a situação.
O que olhar para não deixar a fila inchar silenciosamente
Duas métricas do SQS bastam para você dormir tranquilo:
ApproximateNumberOfMessagesVisible, quantas mensagens estão prontas para serem consumidas. Crescimento sustentado significa que o consumer não está acompanhando o produtor.ApproximateAgeOfOldestMessage, idade da mensagem mais antiga não consumida. Crescimento aqui é o sinal de alerta clássico, alguma coisa travou.
Aplicar nas filas principais e na DLQ cobre a maior parte dos cenários. Acompanhando isso, a gente percebe o problema antes do cliente ligar.
Conclusão
Em poucas linhas de configuração, saímos de "consumer em loop silencioso contra gateway downstream" para "mensagens isoladas na fila morta e redrive nativo devolvendo tudo depois do conserto". DLQ, retentativas e redrive transformaram ruído operacional em sinal acionável. Os ganhos:
- Sem código de orquestração de retentativa, o SQS faz por você via
RedrivePolicy+maxReceiveCount. - Falhas isoladas, o que falhou foi para a DLQ, o que está saudável continua passando.
- Reprocessamento confiável,
start-message-move-taskdevolve tudo, sem script artesanal. - Observabilidade simples, duas métricas do SQS cobrem a maioria dos cenários.
E tudo isso rodando em LocalStack na sua máquina, custo zero para experimentar à vontade.
Com isso, encerramos a série Dominando Mensageria na AWS. Saímos do Point-to-Point básico no episódio 1, passamos pelo fan-out com SNS + SQS no episódio 2, e fechamos o trio com resiliência sob falha. Que essa base acompanhe você nas próximas arquiteturas event-driven que for desenhar. Até a próxima! 🚀
Fontes
- Amazon SQS, Using Dead-Letter Queues
- Amazon SQS, RedrivePolicy e RedriveAllowPolicy
- Amazon SQS,
start-message-move-taskAPI Reference - Amazon SQS, Visibility Timeout
- Amazon SQS, Available CloudWatch Metrics for Amazon SQS
- Amazon SQS, Capturing problematic messages
- AWS Compute Blog, Using Amazon SQS Dead-Letter Queues to Control Message Failure
- Spring Cloud AWS 4.0, SQS Reference (
@SqsListenere Error Handling) - LocalStack, SQS Documentation
- LocalStack, Auth Token Signup